
Abdessamad Nafissi
Linguist & Natural Language Processing engineer
About me
Translator & language expert with an extensive background in linguistics, I expanded my skill set to cover the area of Natural Language Processing. A subfield of linguistics and computer science that trains computers understand human language through codes and algorithms. In other words, it is where Linguistics and Computer Science meet.
I studied Math and Python programming language, and I have built a strong relationship with various NLP libraries such as: SpaCy, NLTK, Scikit-learn, PyTorch, Pandas, Huggingface... and cloud services like Microsoft Azure. I can design, build, test, deploy and monitor Machine Learning solutions for different use cases.I enjoy learning new stuff and keep up with such a fast-paced environment.
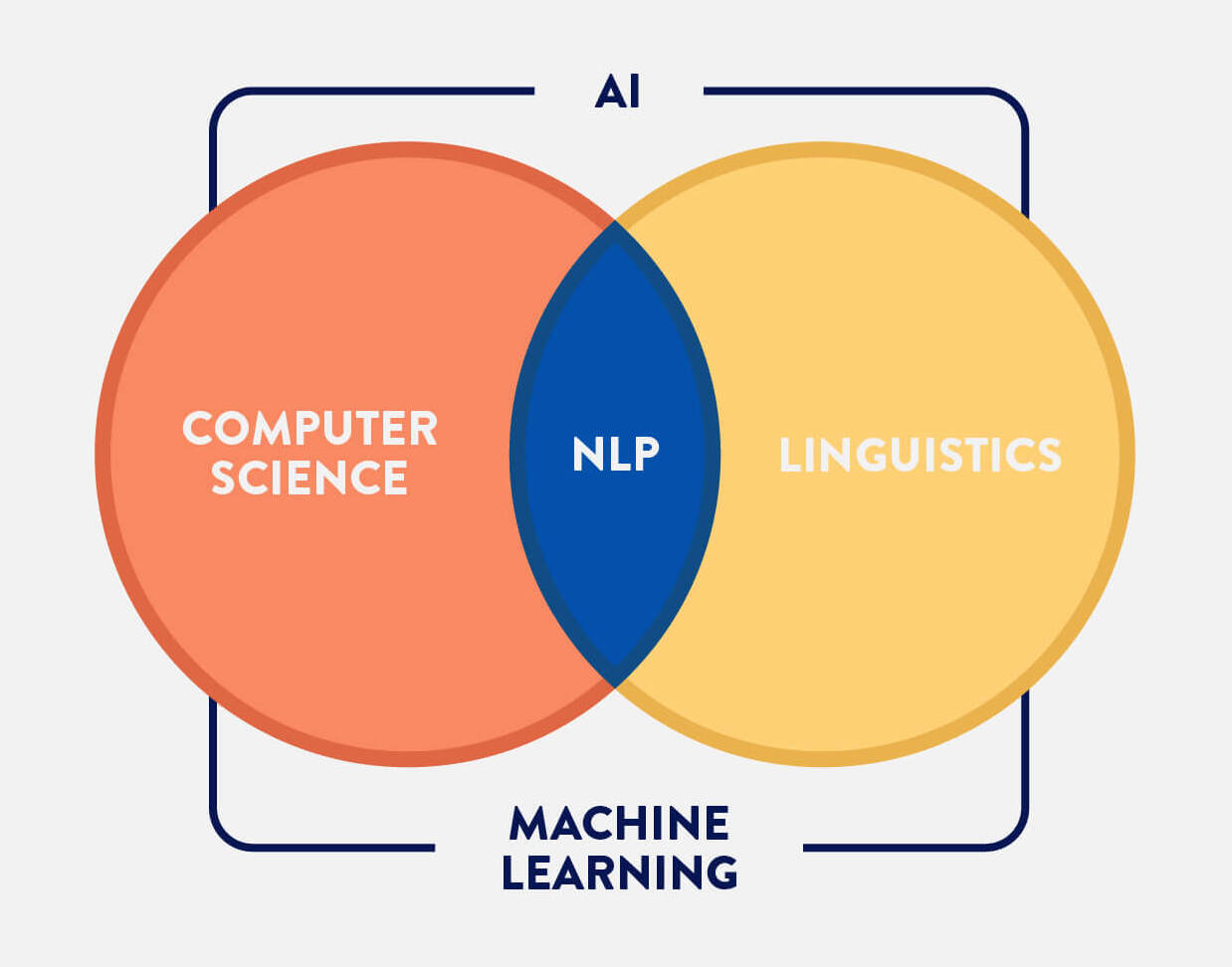
Skills
I develop custom NLP solutions for a variety of industries and use cases like:
All of these Natural Language Processing features can be utilized to perform large-scale analysis, gain real insights of the data, improve customer satisfaction, better understand the market.
Portfolio
One of my NLP projects I manage to capture:
Custom NLP pipeline
This YouTube video captures my journey to building a custom Natural Language Processing pipeline for sentiment analysis from social media text data. A pipeline that converts emojis to text with semantic values, cleans the data from any noise without compromising the semantic or the syntax, parses urls and extract domain from them... The pipeline was coded in way that can be customized and adapted to any, if not all, use cases that deals with text data without any complexities.
A good visualization tells a story
Data visualization gives us a clear idea of what the information means by giving it visual context through graphs, wordcloud or pie to name a few. This makes the data more natural for the human mind to comprehend and therefore makes it easier to identify trends, patterns, and outliers within large data sets. These two examples below clearly illustrates the sentiment analysis distribution as well as the most frequent words in the text data.


Get in touch
For more information do not hesitate to contact me. For open source projects find my Github at the bottom.
©{{ year }} • Abdessamad Nafissi • from HTML5 UP.